OpenVINO by Intel CVPR-2022

How to get quick and performant model for your edge application. From data to application.


How to get quick and performant model for your edge application. From data to application.
Organizers:
Paula Ramos, Raymond Lo, Helena Kloosterman, Samet Akcay, Zhuo Wu & Yury Gorbachev
Overview:
One of the most important technology shifts of recent times is to use edge processing to collect, process, analyze and make decisions on-site or send data to the cloud. In addition, the increasing connection of millions or billions of sensors to the cloud will have a huge impact on bandwidth consumption, which will make low-latency applications unfeasible in the cloud. So, thinking about intermediate or full processing at the edge and sending reduced information to the cloud would reduce the impact on data transfer/processing, with another possible solution being the emerging 5G networks [1]. Currently, Intel through its OpenVINO toolkit contributes mostly generating low latency computing systems at the edge, while retaining the same accuracy as the original models. [2].

Figure 1. Optimization pipeline for deep learning models
Not all deep learning (DL) models have been designed to run on the resource-constrained edge. Most deep neural networks (DNNs) have been designed to achieve the highest possible accuracy, without considering a trade-off between performance and accuracy to develop more computationally efficient DLs [3]. A common approach provided by most DL frameworks to accelerate inference is, to quantize a model to INT8 precision [4] and to consider a matrix multiplication reduction (sparsity) to obtain good results [5]. OpenVINO Toolkit offers several tools for making a model run faster and take less memory: Model Optimizer, Post-training Optimization Tool (POT), and Neural Network Compression Framework (NNCF). However, these good results also will depend on the dataset distribution you are using in between, training, testing, and validation. To address these challenges, OpenVINO has developed a convenient environment (OpenVINO Training Extensions OTE) (Figure 1) to train a new model with more efficient architecture using your own dataset, keeping the distribution of itself and getting the best possible results to deploy your model into the edge [6], achieving a 3.6x increase in processing speed compared to the original FP16 model (SSD-300) [5].
Prework:
You would need a computer (laptop/tablet) with an Intel Core Processor. Alternatively, you could access the Intel hardware via Intel DevCloud for the Edge. Also, we recommend participants to be familiar with basic concepts of computer vision and deep learning, such as convolutional neural networks and PyTorch and TensorFlow frameworks. Note: A laptop with a built-in webcam is a plus for testing out the interactive demos.
- Follow the instructions on this Wiki page
- Run the notebooks 301, and 401
- Share screenshots of your results in our repository. Discussion thread CVPR - Prework
We will have some prizes at the end of the tutorial for whom make this prework.
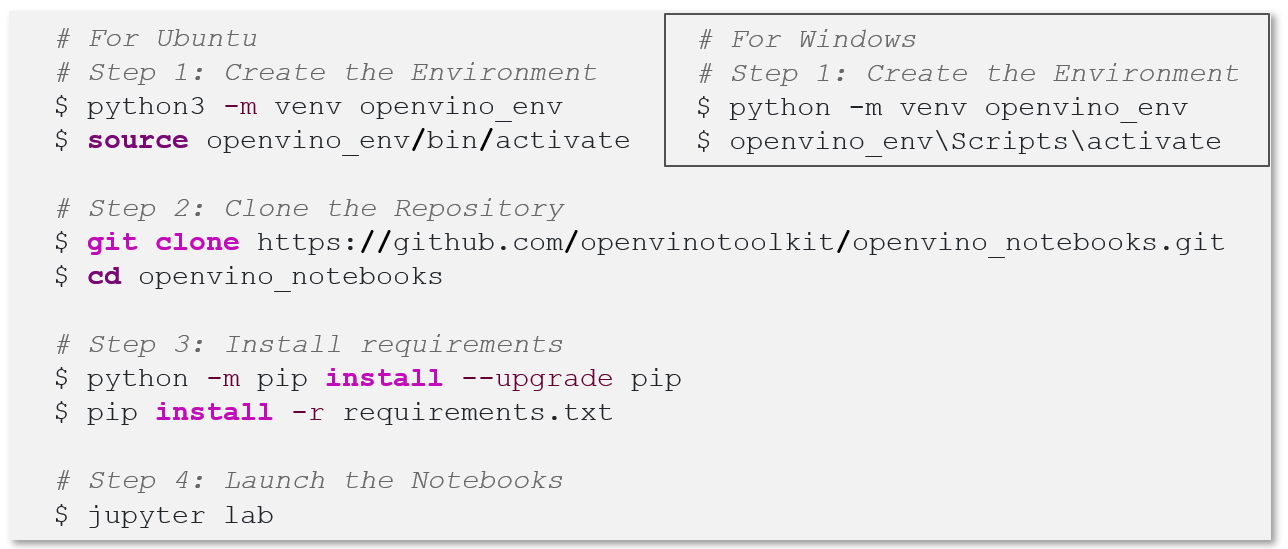 Figure 2. Installation steps for Windows
Figure 2. Installation steps for Windows
Outline
- Prework – OpenVINO Notebooks installation.
- General aspects of OpenVINO.
- Hands-on experience – OpenVINO Notebooks. Exercise 1
- General Aspects of Optimization process
- Model Optimizer. Exercise 2
- Post training Optimization. Exercise 3
- NNCF with segmentation model. Exercise 4
- Improve performance with AUTO plugin. Exercise 5
- OpenVINO Training Extensions (OTE).
- Object Detection with OTE. Exercise 6
- Anomalib by OpenVINO.
- End2End experience. Evaluate and deploy your solution using Anomalib. Exercise 7
Slides
Please use this link to download our presentation.
References
[1] Y. Ai, M. Peng and K. Zhang, “Edge computing technologies for Internet of Things: a primer,” Digital Communications and Networks, 2017.
[2] Intel Corporation, “OpenVINO™ toolkit Documentation,” Intel Corporation, 2021. [Online]. Available: https://docs.openvino.ai. [Accessed 9 12 2021].
[3] A. Kozlov, I. Lazarevich and V. Shamporov, “Neural Network Compression Framework for fast model inference,” arXiv, p. 13, 2020. https://arxiv.org/abs/2002.08679
[4] Pytorch, “QUANTIZATION,” Torch Contributors, 2019. [Online]. Available: https://pytorch.org/docs/stable/quantization.html. [Accessed 9 12 2021].
[5] A. Kozlov, M. Kaglinskaya, I. Lazarevich, A. Dokuchaev and Y. Gorbachev, “Model Optimization Pipeline for Inference Speedup with OpenVINO™ Toolkit,” Intel Corporation, 31 January 2021. [Online]. Available: https://www.intel.com/content/www/us/en/artificial-intelligence/posts/model-optimization-pipeline-with-openvino-toolkit.html. [Accessed 9 12 2021].
[6] Intel Corporation, “OpenVINO™ Training Extensions,” Intel Corporation, 2021. [Online]. Available: https://github.com/openvinotoolkit/training_extensions. [Accessed 9 12 2021].